Our gateway
Orca
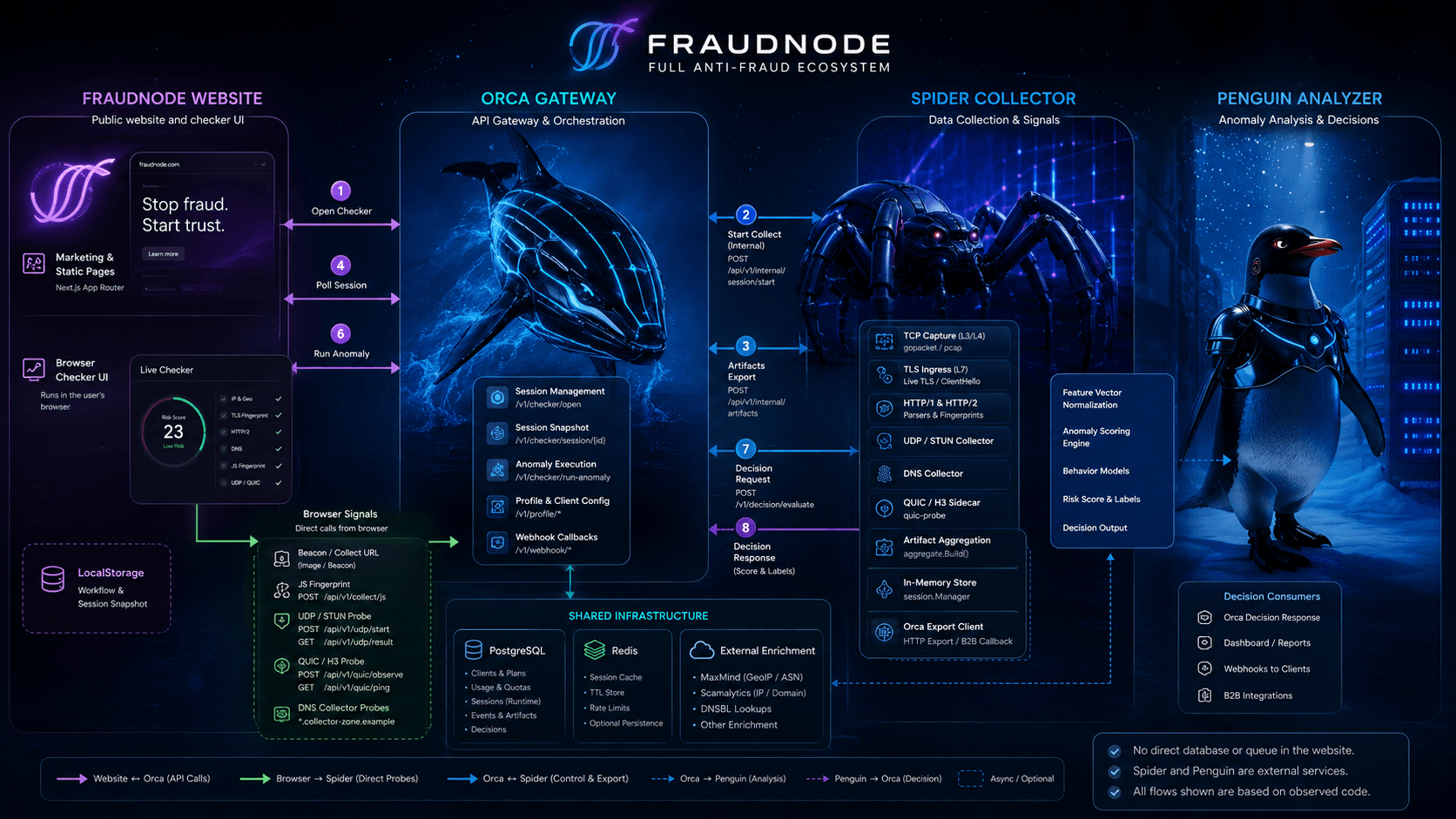
Orca is the gateway with teeth: it opens sessions, accepts collector evidence, normalizes artifacts, and keeps the public site talking to one stable API.
Control plane with a memory
Orca starts sessions, signs internal calls, keeps policy close, and remembers what happened. The browser never receives service secrets, Spider does not become a business rules department, and the site gets one clean contract instead of a drawer full of cables labeled maybe.
Parser runtime
Spider sends raw evidence; Orca turns it into stable blocks the site can read: IP, TCP, TLS, HTTP, JS, GEO, DNS, blacklist, UDP/QUIC, and anomaly. Each block can be ok, partial, missing, or error, because reality sometimes arrives late and wearing a fake mustache.
T0 first, T1 when the plot thickens
T0 is the fast lane: TCP, TLS, HTTP, JS, and quick enrichment for an early decision. T1 is the extended lane: DNS, UDP, QUIC, reputation, and heavier follow-up. Orca keeps those stages separate so the product can be fast without pretending every slow signal is already home.
Storage without drama
For Checker and demo/trial flows, Orca stores raw envelopes, normalized blocks, audit traces, and analyzer results. For high-throughput B2B, it can run compact or no-persist modes. Same contract, different appetite. Like ordering coffee for a meeting, but nobody argues about oat milk in the API.
Replay is not a party trick
Snapshots carry artifact versions, correlation IDs, timing, missing blocks, and deterministic replay metadata. That means a later anomaly check can run from the stored evidence instead of asking the user to please blink, reload, and reproduce Tuesday.
B2B is a different tempo
The website can show a full checker story, but B2B often wants the short answer before checkout loses patience. Orca supports compact T0 checks, async T1 callbacks, quotas, key ownership, and tenant isolation, while keeping Spider and Penguin behind the curtain where service secrets belong.
Why it is called Orca now
A plain gateway forwards traffic and looks busy. Orca coordinates: session policy, quotas, storage, enrichment, replay, analyzer calls, and block contracts. At some point the front desk became mission control, and we stopped pretending it was only handing out visitor badges.
Why the site only talks to Orca
The frontend should not know Spider internals, Penguin secrets, or which enrichment module had a complicated morning. Site code asks Orca for checker blocks. Orca handles the contract, the timing, the upstream weirdness, and the support-friendly trace ID.